As far as I can tell, the only attempt I’ve seen at standardization of VDJ annotation file format is VDJML.
Here’s most of it in a screenshot:
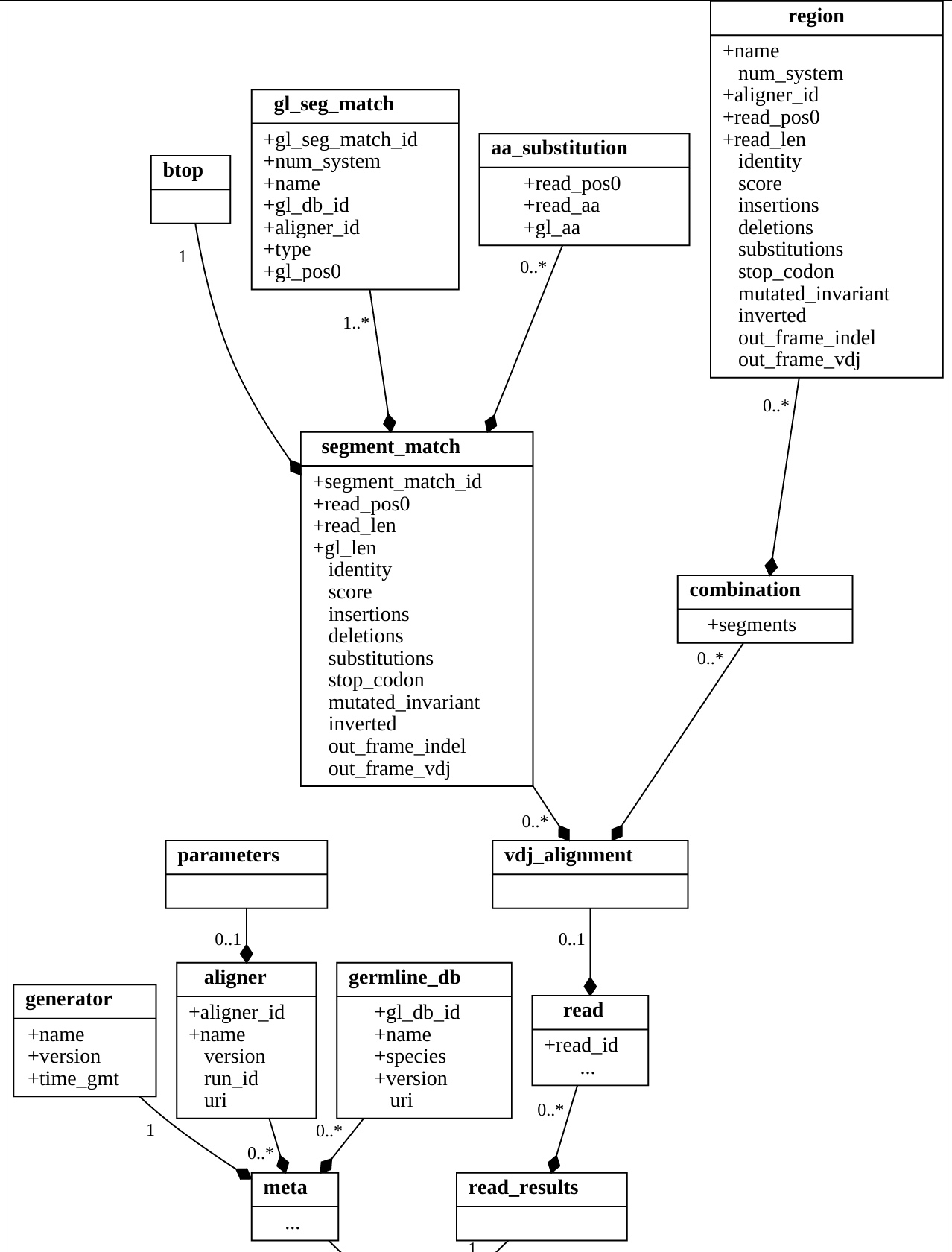
Do people know of other formats? Comments on this one?

As far as I can tell, the only attempt I’ve seen at standardization of VDJ annotation file format is VDJML.
Here’s most of it in a screenshot:
Do people know of other formats? Comments on this one?
I think in general VDJml strikes a good balance between completeness and simplicity. There are just two points I came across that could be improved:
There is no easy way to annotate synonymous mutations (in comparison to the reference sequence). There is a bulk mutation count keyword (“substitutions”) and an “aa_substitution” structure for mapping non-synonymous mutations but neither of those allows to perform the above mentioned annotation. The information can be encoded/extracted in/from the BTOP string, but this is not a very straight-forward way if you think about database querys.
There is no structure that would allow the linkage of several reads as being derived from the same cell.
I’d also like to add a mirrored schema in JSON, which is more human readable (IMHO) and more web-friendly, to a wish-list.
I do like JSON as well, though I suppose my wish list would focus more on having a standardized tabular/CSV format that would be a lower barrier for software authors to use. One could convert such a simple format to a richer format as needed.
Steve Kleinstein mentioned that they were hoping to put something like that together. @javh, do you know anything?
This is the tab-delimited format that we are currently using for our tools: Change-O Data Standard
It’s actually a (mostly) direct mapping of VDJML, though this might not be obvious from the schema. We are planning to integrate VDJML into Change-O, with conversion between our tab-delimited and the XML format, we just have a little data structure refactoring to do in our code before adding VDJML support. Lindsay Cowell’s group has already written the python bindings for the API.
@bussec We definitely didn’t take VH:VL paired data into account when designing the schema originally, but it would be a good thing to add. As it stands, I think it would support VH:VL data fine through custom attributes in the <read> element:
The schema also allows some user-defined elements and attributes, which may
appear under vdj:meta and vdj:read elements. User-defined elements and attributes,
should have namespaces other than vdj.
Where the <read> would be annotated with a sample, well number, droplet barcode, etc defining the VH:VL pairing criteria. But, to me, pairing definitely seems like something that should be standardized.
As far as R/S substitutions, I think opinions are pretty mixed on this. The idea was to exclude attributes from the schema that could be classified as “analysis” output, which would then be handled by addition of other elements under <read>. For the first draft at least, the focus was strictly on V(D)J aligner output.
Any other input you could provide I’m sure would be most welcome.
The suggestions from bussec are good, and I have filed them in our issue tracker for addition. We welcome additional suggested revisions and additions as well.
We also have a TSV that is generated at the same time as the VDJML. I would expect it to map pretty closely to the change-o standard, but I will take a look to confirm.
regarding a TSV being a lower barrier, we have software that reads and writes VDJML that can be accessed via python, so software authors shouldn’t have to write their own VDJML parser. Does this address your concern?
We had been having regular VDJML development calls open to anyone interested in influencing it. We stopped having them when the primary developer left, but we have now replaced him and will restart the calls. If anyone from this list is interested in participating, just let me know.
Thanks for your openness to comment, @lindsay.cowell!
Yes, please do. It would be great to have a standard TSV format alongside with the XML-based format.
That’s great, but I also mean a lower barrier for post-analysis: TSV formats can be easily manipulated using spreadsheet software, programming languages like R, or even command-line utilities. I should also note that not all alignment software is written in Python.
That said, I think that a rich reference format like VDJML is a great step forward. Here are a couple of other things to think about:
good point about the TSV. We should be able to easily have a TSV that is aligned between VDJServer and change-o and VDJML. I plan to post comments next week regarding the comparison of the change-o and VDJServer TSVs, although I expect them to align pretty well.
I also agree that adding annotation ala @tbkepler comment at the May meeting is a good idea, and we would be happy to add that. I suppose we would need a tag to capture the value and a tag to capture the specific software/method used to generate the value.
also added clone ID tags and JSON “schema” to our issue tracker.
Thanks for all the great suggestions!!
I think the probabilistic annotation would fall into match_metrics in <Segment_match>. I believe that’s score in the old schema (the screenshot).
Ah, OK, that’s helpful. Thanks, @javh.
If I understand correctly, the 0...* means that we can have multiple segment_match annotations for a given sequence. The idea would be to present multiple alternatives, each with weight.
Yes, that’s my understanding of how the 0-to-many relationship would work - as an alternative representation of a “hit” table.
both of Jason’s comments are correct. We were using the match_metrics to capture IgBlast alignment scores, but it could obviously be used to capture other metrics. And we do capture multiple hits.
Thanks!
I would also strongly promote the use of a modern serialization framework for this, i.e., one of Apache Thrift, Apache Avro, or Google Protocol Buffers. Much has been written about the advantages of these, with a good summary here:
http://martin.kleppmann.com/2012/12/05/schema-evolution-in-avro-protocol-buffers-thrift.html
The frameworks have very efficient binary representations, are compatible with JSON, offer RPC IDLs, support schema evolution, and generate efficient code for in-memory models in many programming languages that are all binary compatible. They are also all compatible with the Parquet file format, which is incredibly efficient for analytical queries and compression, and for use with cloud-compatible file formats. All of these tools are industry-standard at big data companies, and are heavily maintained by the open source community. Mostly, they unburden scientists from dealing with the sometimes horror-show of file format/encoding issues.
Great comments and excellent ideas came out of the AIRR community meeting. The VDJML team is very interested in helping define a new community standard. One thing that came out of the meeting is the different preferences people had towards file formats: TSV, JSON, XML, etc. Here @laserson comments are spot on in that we should use a serialization framework that allows any of these file formats to be generated from some base data representation, taking that issue out of the equation and let’s us focus on the data model. I’d like to start with a prototype implementation but my first question is which of these frameworks should we use?
While our general goal is to define a common data model for VDJ annotation, I think we need to specifically allow for extensions(maybe not right word) to that data model. Each tool will not provide all annotation, they may in fact only provide some piece of the total annotation based upon their specific algorithm. For example, a tool with a specialized algorithm to define clones would only stick in annotation information about clones. We want a data model that
Apache Thrift looks interesting but it seems to focused more on defining interfaces versus a data definition language.
Apache Avro has the nice feature that the data schema is embedded with the data, which is great for allowing extensions and different versions of the data model that tools can utilize without recompiling, etc. It also seems to support many languages. It is unclear whether there are automatic conversions tools, i.e. transform the Avro binary file into a TSV for example?
Protocol Buffers sounds good as it is meant to be smaller and faster XML, which makes sense as I don’t think we need any of the complicated data model features in XML. It doesn’t provide the schema with the data, so reflection is harder to do (I think), we would need to carefully design the data model so tools can check whether specific annotation data is available or not.
Of course XML has a data schema language (XSD) for defining the data model, which is what we have for VDJML V1. In theory this should allow the same things that Avro and Protocol Buffers allow with code generation, automatic parsing and etc. However, it seems to me that the XML community didn’t really go this route, and many codes essentially hard-code the interpretation of the data model. I do see some stuff for Java but not much for other languages, anybody know? I suppose another point is that XSD allows for such a sophisticated data model, that this ends up being a complicated task.
Are there any other frameworks we should consider? I tend to like Avro because the schema is embedded with the data, is there any advantage to use Protocol Buffers over Avro?